Kelly Shreeve

Data Scientist with M.A. in sociology, B.A. in environmental sociology, and 5+ years' experience teaching statistics. Completed TripleTen's 10 month data science bootcamp and a real-world data science externship with DataSpeak. Currently accepting data analysis and statistics consulting projects May 2024.
View My LinkedIn Profile
Classifying Movie Reviews
Project Overview
Purpose
Train a model to automatically detect reviews as positive or negative polarity from a dataset of IMBD movie reviews with polarity labelling. Achieve an F1 score of at least 0.85.
Techiniques
Tokenization, Lemmatization, BERT, gradient boosting.
Installation and Setup
Codes and Resources Used
- Editor Used: Visual Studio Code
- Python Version: 3.10.9
Python Packages Used
- General Purpose: math, numpy, re, tqdm
- Data Manipulation: pandas
- Data Visualization: matplotlib, seaborn
- Machine Learning: sklearn, LightGBM
- Natural Language Processing: NLTK, spaCy, torch, transformers
Data
Data Files
imdb_reviews.csv
Features
- review - the review text
- start_year - year or release
- title_type - type of movie
- ds_part - ‘train’/’test’ for the train/test part of the dataset, correspondingly
Targets
- pos - the target, ‘0’ for negative and ‘1’ for positive
Data Acquisition
The data were provided by TripleTen’s Data Science bootcamp.
Data Preprocessing
Variables missing data were all missing less than 15% of observations. Categorical missing values were filled with ‘unknown’ and quantitative missing values were imputed with medians. Duplicates were cleaned from the dataset.
Code Structure
├── LICENSE
├── README.md
│
├── images
│ └── movie_clipart.png
│ └── important_features.png
│
└── notebooks
└── nlp_review_analysis.ipynb
Results and Evaluation
Exploratory Analysis
The number of movies per year generally increases over time until 2006, when we see a sharp decline in number of movies produced per year. There are generally similar numbers of positive and negative reviews per year.
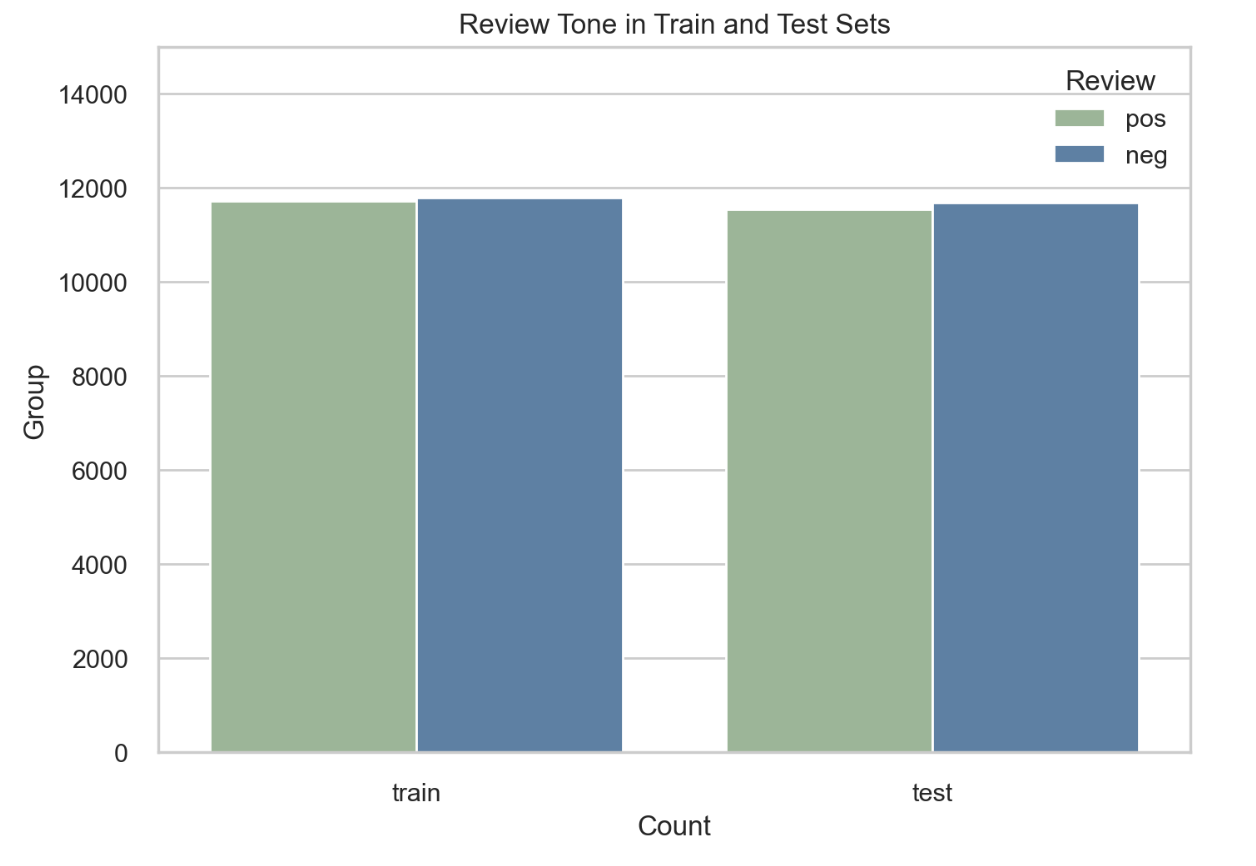
There are similar numbers of positive and negative reviews in the training and test sets. Additionally, the classes are mostly balanced in both the training and test sets.
Train Results
Logistic Regression with NLTK, TF-IDF
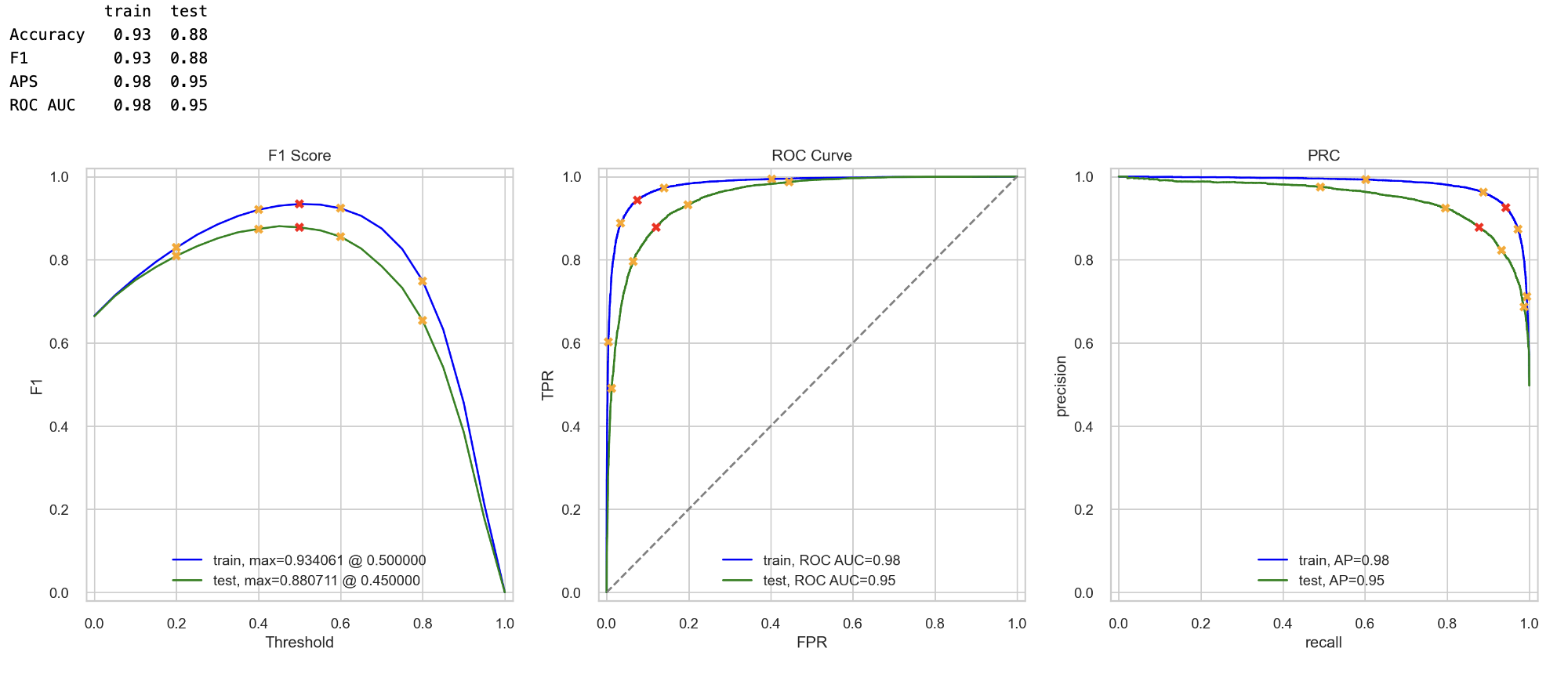
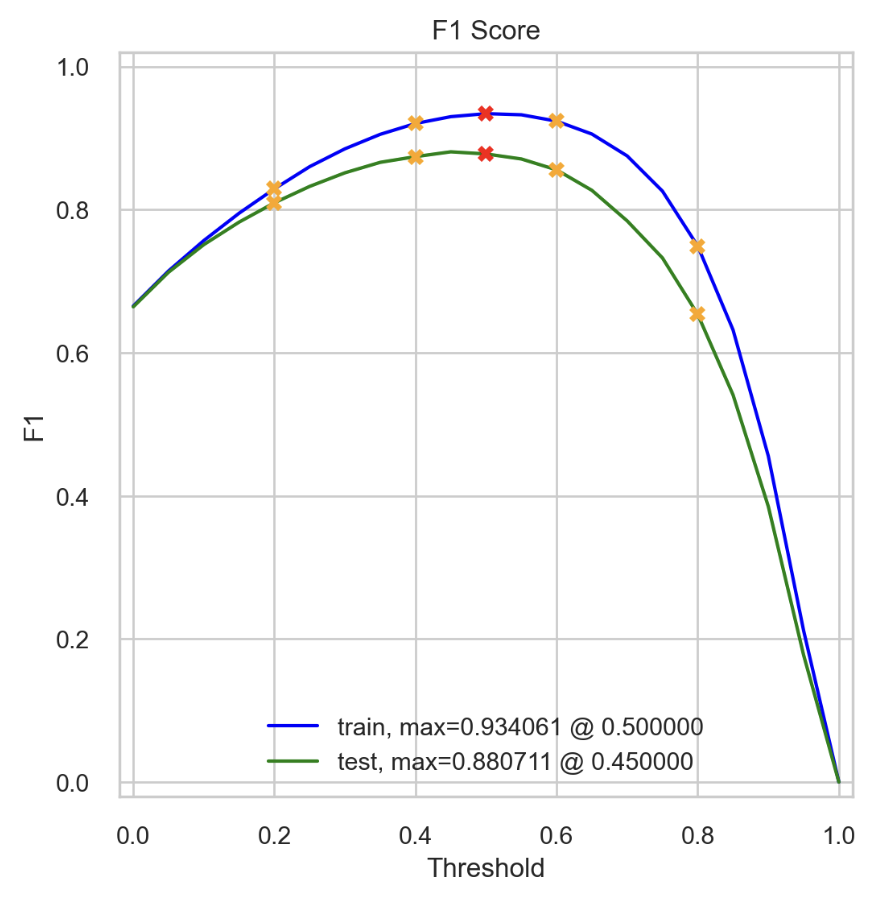
Logistic regression with text vectorized with NLTK TF-IDF was able to achieve a maximum F1 score of 0.88 at a threshold of 0.45 on the test set. It had a validation ROC AUC of 0.95 and a validation PRC of 0.95. This model is good at classifying reviews based on media type, year, runtime, and review text.
Test Results
Predicted probabilty of positive review using the NLTK TF-IDF logistic regression:

Four models were trained and each did fairly well classifying the training set. Models are summarized as follows:
- NLTK, TF-IDF, and Logistic Regression (F1 = 0.88)
- SpaCy, TF-IDF, and Logistic Regression (F1 = 0.87)
- SpaCy, TF-IDF, and LightGBM (F1 = 0.87)
- BERT, Logistic Regression (F1 = 0.85)
The best model is the logistic regression trained with NLTK, TF-IDF. This model achieved and F1 = 0.88 on the text set.
Conclusions and Business Application
Conclusions
The best model was the Logistic Regression trained with NLTK lemmatization and TF-IDF text vectorization. BERT would likely perform better, with more time to tune on a larger training set.
Business Application
The Film Junky Union can feel confident putting this model into use, knowing it will correctly predict about 90% of movie reviews as positive or negative in tone.
Future Research
With additional time, BERT could be further fine tuned on additional data. Additionally, more tuning parameters could be tested on gradient boosting models.