Kelly Shreeve

Data Scientist with M.A. in sociology, B.A. in environmental sociology, and 5+ years' experience teaching statistics. Completed TripleTen's 10 month data science bootcamp and a real-world data science externship with DataSpeak. Currently accepting data analysis and statistics consulting projects May 2024.
View My LinkedIn Profile
Predicting Gold Recovery from Ore
Project Overview
Purpose
Build a multi-output regression that minimizes symmetric Mean Absolute Error (sMAPE) when predicting gold recovery from ore. After identifying the best model, determine which factors are unprofitable.
Techniques
Linear Regression, Decision Tree Regression, and Random Forest Regression were tuned and cross-validated to determine which model best minimizes sMAPE on the training set.
Installation and Setup
Codes and Resources Used
- Editor Used: Visual Studio Code
- Python Version: 3.10.9
Python Packages Used
- General Purpose: numpy
- Data Manipulation: pandas
- Data Visualization: matplotlib
- Statistical Analysis: statsmodels
- Machine Learning: sklearn
Data
Data Files
Three data sets contain information on the full set, training set, and test set:
gold_recovery_full.csv
gold_recovery_train.csv
gole_recovery_test.csv
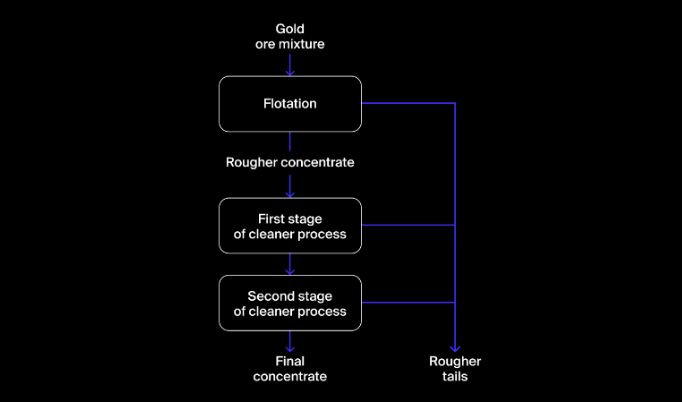
Datasets contain information on input and output measures for each stage in the gold recovery process:
- Inputs are floatbank parameters such as air and water level and concentrations of metal and solids in the ore.
- Outputs are concentrations of metals and other solids in the concentrate and in the tails.
Observations close to each other in time are often similar.
Feature naming construction:
[stage]_[parameter_type].[parameter_name]
Data Acquisition
The data were provided by TripleTen’s Data Science bootcamp.
Data Preprocessing
Data were checked for missing values and duplicates. Missing values were imputed with the average of forward and backward fill. There were no duplicates.
Code Structure
├── LICENSE
├── README.md
│
├── images
│ └── final_regression.png
│ └── gold_stages.png
│ └── recovery_process.png
│
└── notebooks
└── gold-recovery-analysis.ipynb
Results and Evaluation
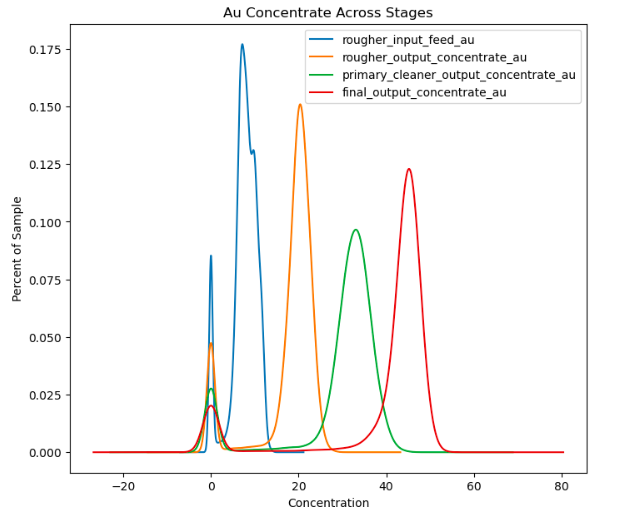
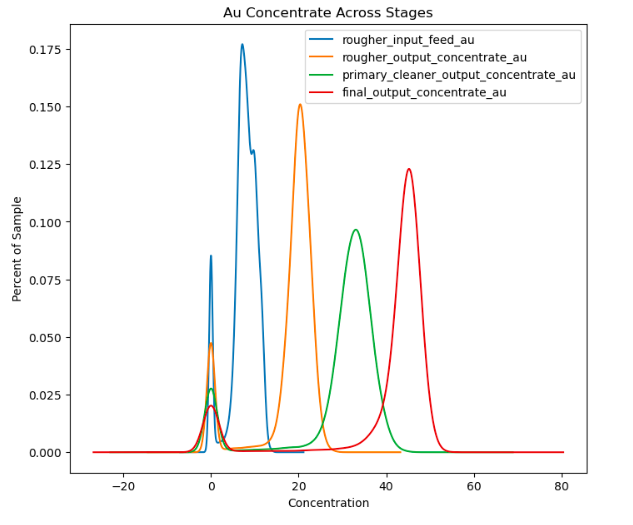
Concentration of gold ore tends to increase though each stage of the recovery process.
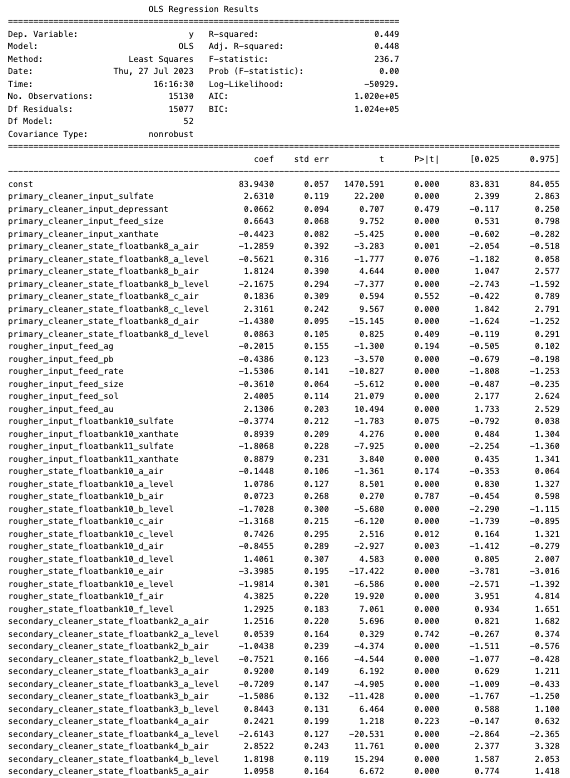
Linear Regression achieved the best training sMAPE of 12.30 and this was confirmed with a final sMAPE of 7.30 on the test set. Upon viewing the regression output, some floatbank states were not signficant, though all of the chemical inputs were. The company may be able to loosen control over the floatbank states but should continue to be mindful of the chemical inputs during the process.
Acknowledgments/References
TripleTen’s Data Science bootcamp for providing the project and the data.