Kelly Shreeve

Data Scientist with M.A. in sociology, B.A. in environmental sociology, and 5+ years' experience teaching statistics. Completed TripleTen's 10 month data science bootcamp and a real-world data science externship with DataSpeak. Currently accepting data analysis and statistics consulting projects May 2024.
View My LinkedIn Profile
Final Project: Predicting Telecom Customer Churn
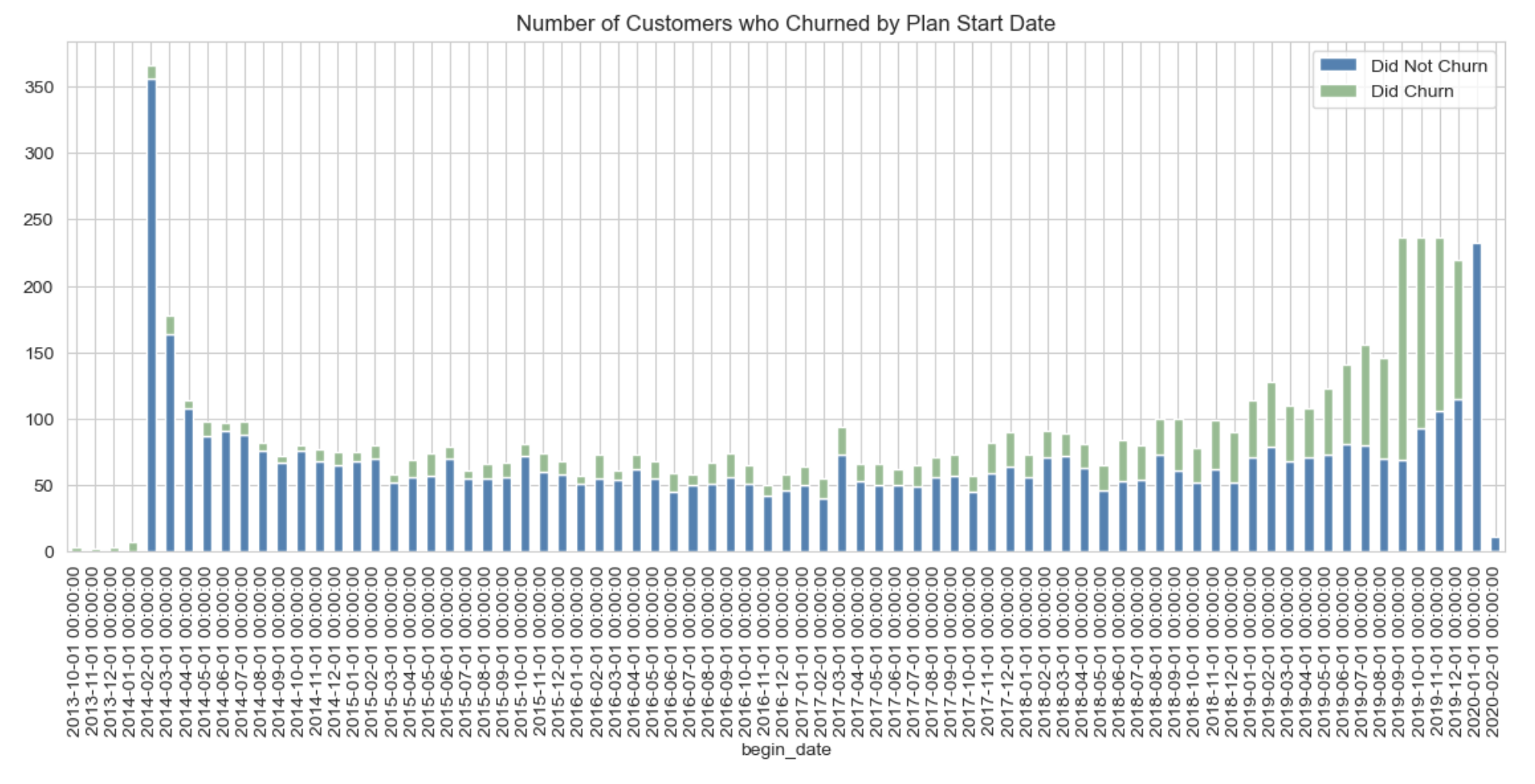
Table of Contents
- Project Overview
- Installation and Setup
- Data Source and Preparation
- Results and Evaluation
- Conclusions and Business Recommendations
1. Project Overview
Background: Telecom operator Interconnect would like to forecast the churn of their clients. If the customer is likely to leave, they will be sent promotions and special plan offers.
Purpose: Fit an imbalanced classification model that accurately predicts which customers are likely to leave the company.
Techniques: CatBoost, LGBM, XGBoost, AdaBoost, pipelines, GridSearchCV, class balancing.
2. Installation and Setup
Codes and Resources Used
- Editor Used: Visual Studio Code
- Python Version: 3.10.9
Python Packages Used
- General Purpose:
numpy, time - Data Manipulation:
pandas - Data Visualization:
matplotlib, seaborn - Machine Learning:
sklearn, imblearn - Gradient Boosting:
catboost, lightgbm, xgboost
3. Data Source and Preparation
contract_df.csv, internet_df.csv, personal_df.csv, phone_df.csv
Target:
- churned: 0 = has not churned, 1 = has churned
Features:
- begin_year: year of contract start date
- type: type of contract
- paperless_billing: customer has paperless billing or not
- payment_method: type of payment method
- monthly_charges: amount customer is charged per month
- total_charges: total payments over life of plan
- internet_service: type of internet service
- gender: male or female
- senior_citizen: whether the customer is a senior citizen
- partner: whether the customer has a partnmer
- dependents: whether the customer has dependents
- multiple_lines: whether a customer has multiple phone lines; ‘no_plan’ for customers who do not have phone
- has_protection: 0 = no proteciton services, 1 = at least one protection service
- has_streaming: 0 = no streaming services, 1 = at least one streaming service
Data Acquisition
The data were provided by TripleTen’s Data Science bootcamp. The full dataset is loaded into the notebook but is proprietary information and cannot be shared online.
Data Preprocessing
Data were checked for missing values and duplicates. The 4 missing values in total charges were filled with the median of total charges. No other duplicates or missing values were found.
The four datasets were merged on customer id to make a comprehensive dataset for all variables.
Four additional features were created:
- begin_year: begin date of service
- has_protection: whether a customer has any of three internet protection services
- has_streaming: whether a customer has either streaming service
- total_internet_services: total number of extra internet services on a customer’s subscription
4. Results and Evaluation
Exploratory Analysis
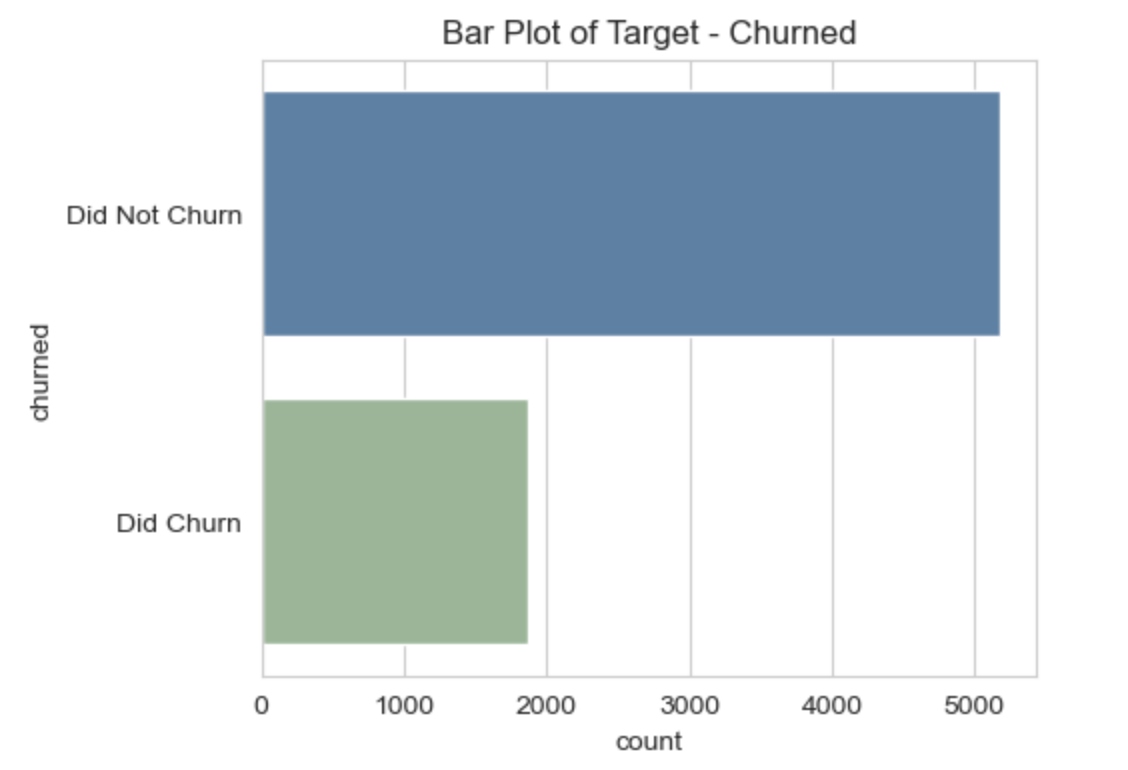
There are fewer customers who churned than did not churn. This is an imbalanced classification problem. Class balancing and weighting techniques will be applied.
Customers who began their contracts in 2014 - 2018 are almost all still with the company.
About 50% of customers who began their contracts in 2019 - 2020 have already churned.
New customers are more likely to leave than old customers.
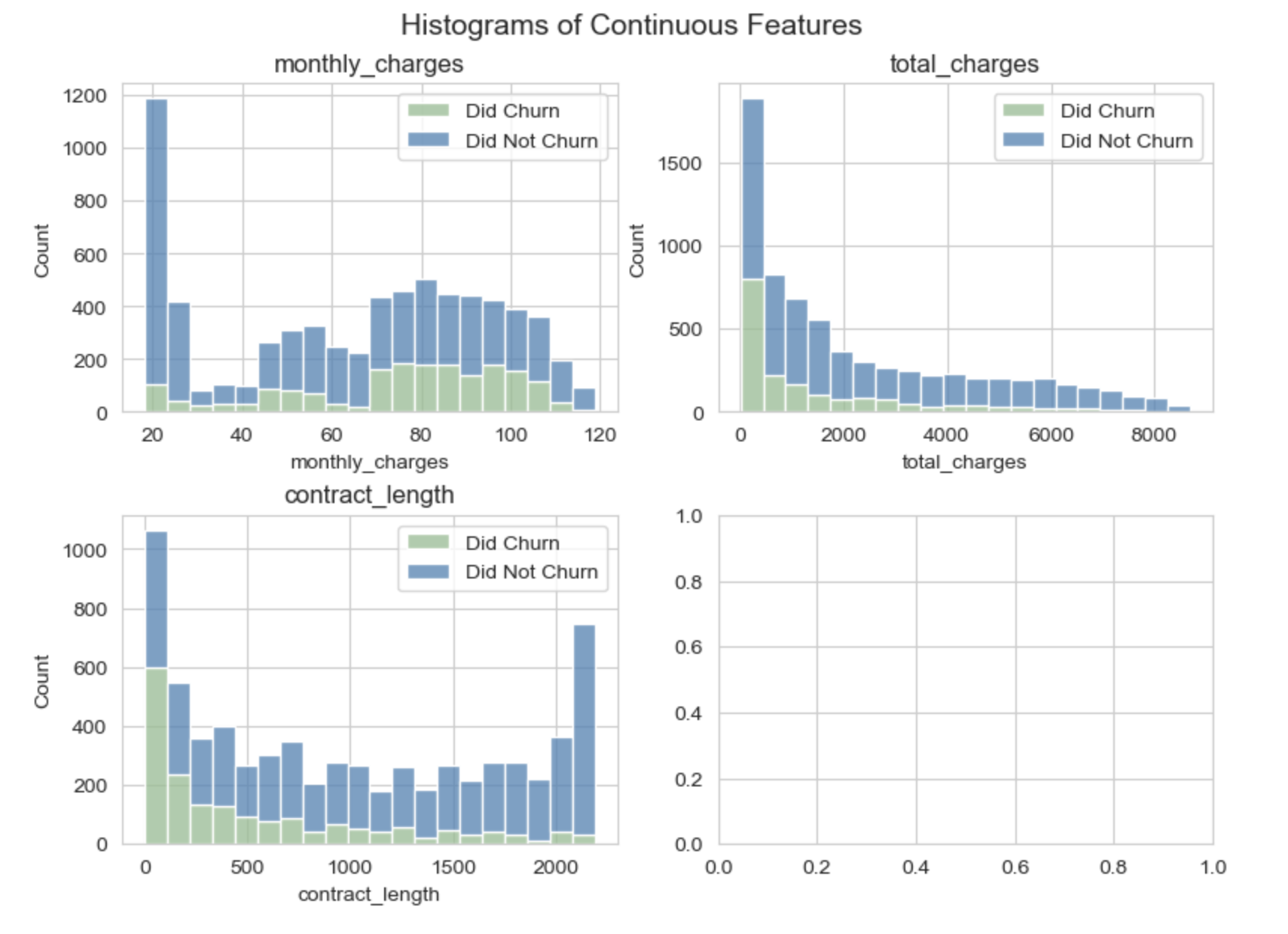
The distribution of monthly charges has three peaks at $20, $50, and $80 per month.
Total charges is highly right skewed, with most people paying close to $0 total and only a few people paying over $6000 over the life of their plan.
Contract length is bi-modal, with many people having contracts less than 100 months or more than 2000 months.
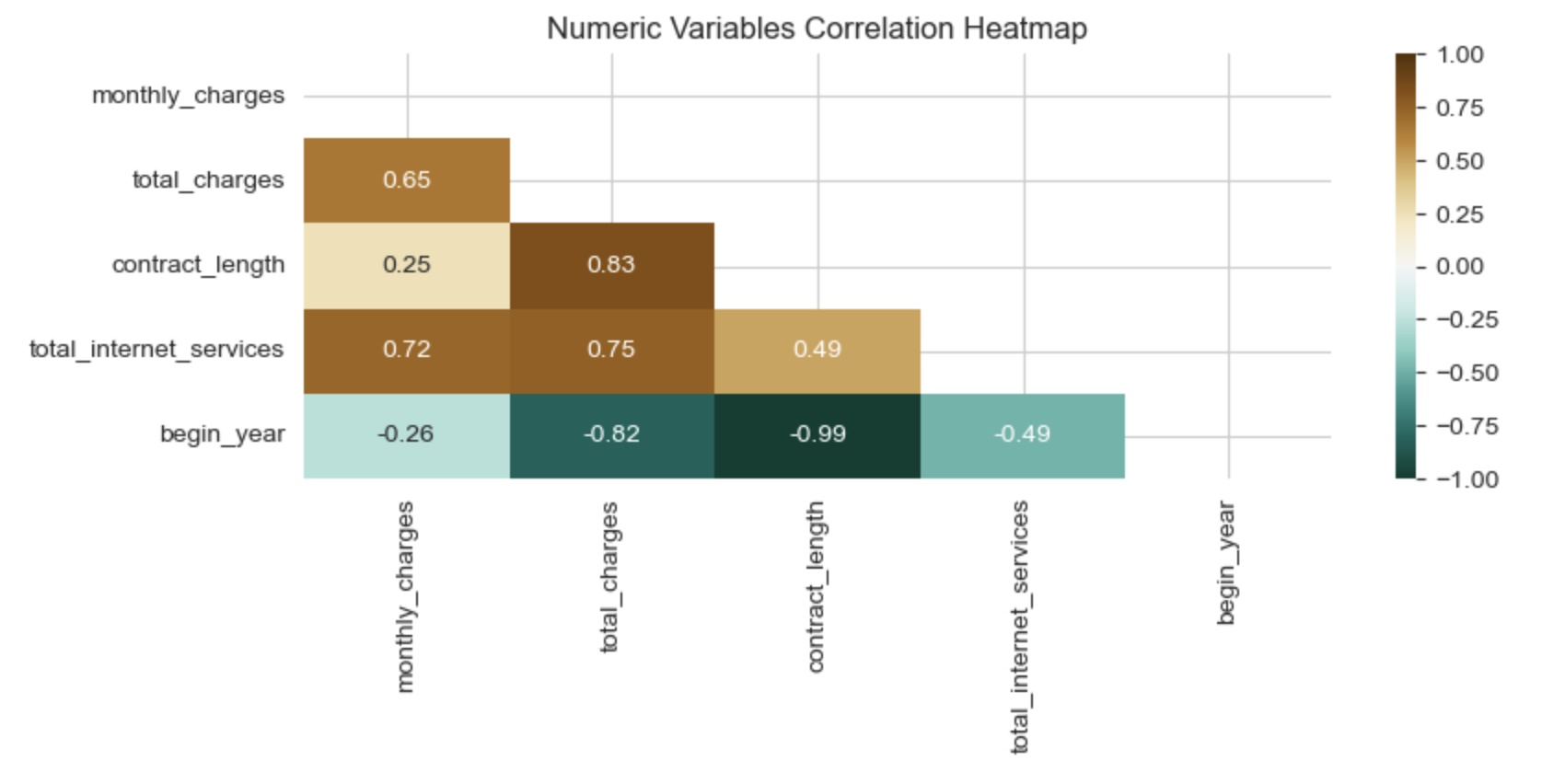
The correlation heatmap shows high correlations between numeric features, representing multicollinearity, and a violation of the assumption of non-multicollinearity. Some features will need to be removed from the model.
Total charges, while highly correlated with begin year (r = -0.82), shares only a moderate correlation with monthly charges (r = 0.65). Tree models are not highly affected by slight multicollinearity. Total charges will be kept in the model.
Begin year and monthly charges have a low correlation with each other and will be kept in the model (r = -0.26).
Contract length and total internet services will be removed from the model.
Train Results
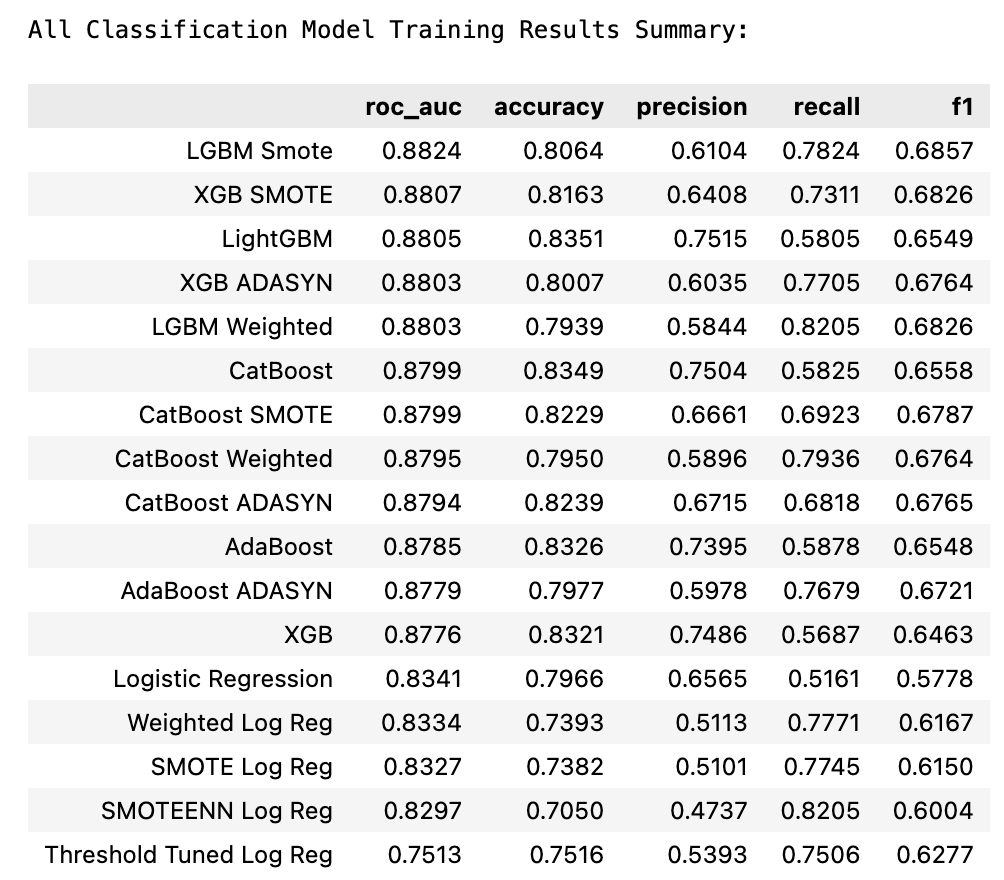
The best model was the LightGBM trained on SMOTE upsampled data. This model achieved the highest scores on roc-auc and accuracy (ROC-AUC = 0.88, accuracy = 0.81). The LightGBM Model will be tested on the test set.
Test Results

The LighGBM Classifier, fit on SMOTE upsampled training data, achieved a lower ROC-AUC on the test set (ROC-AUC = 0.80). This model is likely slightly overfit but still achieves a reasonabl training score.
5. Conclusions and Business Recommendations
Conclusions
LightGBM Classifier achieved the best model fit (ROC-AUCTEST = 0.80, accuracyTEST = 0.80). If this model predicts a customer will churn, there’s about 80% chance the customer will actually churn (precisionTEST = 0.80). Of customers who do churn, the model can be expected to predict about 57% of them (recallTEST = 0.57).
Business Recommendations
Telecom can feel confident implementing this model to predict which customers will churn. They can expect that if the model says a customer will churn, it’s very likely that that customer will indeed churn. The model may miss some customers who will churn, so it’s not a bad idea to offer some additional small promotions across the clientelle. Telecom would do well to focus on keeping new customers, as old customers are likely to continue with the company.
Future Research
More research should be done on the company’s newer customers to determine why they are leaving the company. Follow up surveys and additional promotions with this group could help strengthen new client retention.