Kelly Shreeve

Data Scientist with M.A. in sociology, B.A. in environmental sociology, and 5+ years' experience teaching statistics. Completed TripleTen's 10 month data science bootcamp and a real-world data science externship with DataSpeak. Currently accepting data analysis and statistics consulting projects May 2024.
View My LinkedIn Profile
Predicting Used Car Price
Project Overview
Purpose
Train a regression model that accurately and quickly predicts the market value of a new customer’s car from vehicle make, model, mileage, and other specifications. Minimize RMSE.
Techiniques
One Hot Encoding, Pipelines, GridSearchCV, Linear Regression, Gradient Boosting with CatBoost and LightGBM.
Installation and Setup
Codes and Resources Used
- Editor Used: Visual Studio Code
- Python Version: 3.10.9
Python Packages Used
- General Purpose: math, numpy, re, time
- Data Manipulation: pandas
- Data Visualization: matplotlib, seaborn
- Machine Learning: sklearn
- Gradient Boosting: catboost, lightgbm
Data
Data Files
car_data.csv
Features
- vehicle_type - vehicle body type
- registration_year - vehicle registration year
- gearbox - gearbox type
- power - power (hp)
- model_top125 - 125 most frequent vehicle models
- mileage - mileage (km)
- registration_month - vehicle registration month
- fuel_type - fuel type
- brand_top20 - 20 most frequent vehicle brands
- not_repaired - vehicle repaired or not
- postal_code_trunc1000 - postal code truncated to 1000s place
Targets
- price - used car price (euros)
Data Acquisition
The data were provided by TripleTen’s Data Science bootcamp.
Data Preprocessing
Variables missing data were all missing less than 15% of observations. Categorical missing values were filled with ‘unknown’ and quantitative missing values were imputed with medians. Duplicates were cleaned from the dataset.
Code Structure
├── LICENSE
├── README.md
│
├── images
│ └── correlation_matrix.png
│ └── important_features.png
│ └── pairplot.png
│ └── test_results.png
│ └── train_results.png
│ └── used_car_clipart.png
│
└── notebooks
└── car_price_analysis.ipynb
Results and Evaluation
Exploratory Analysis
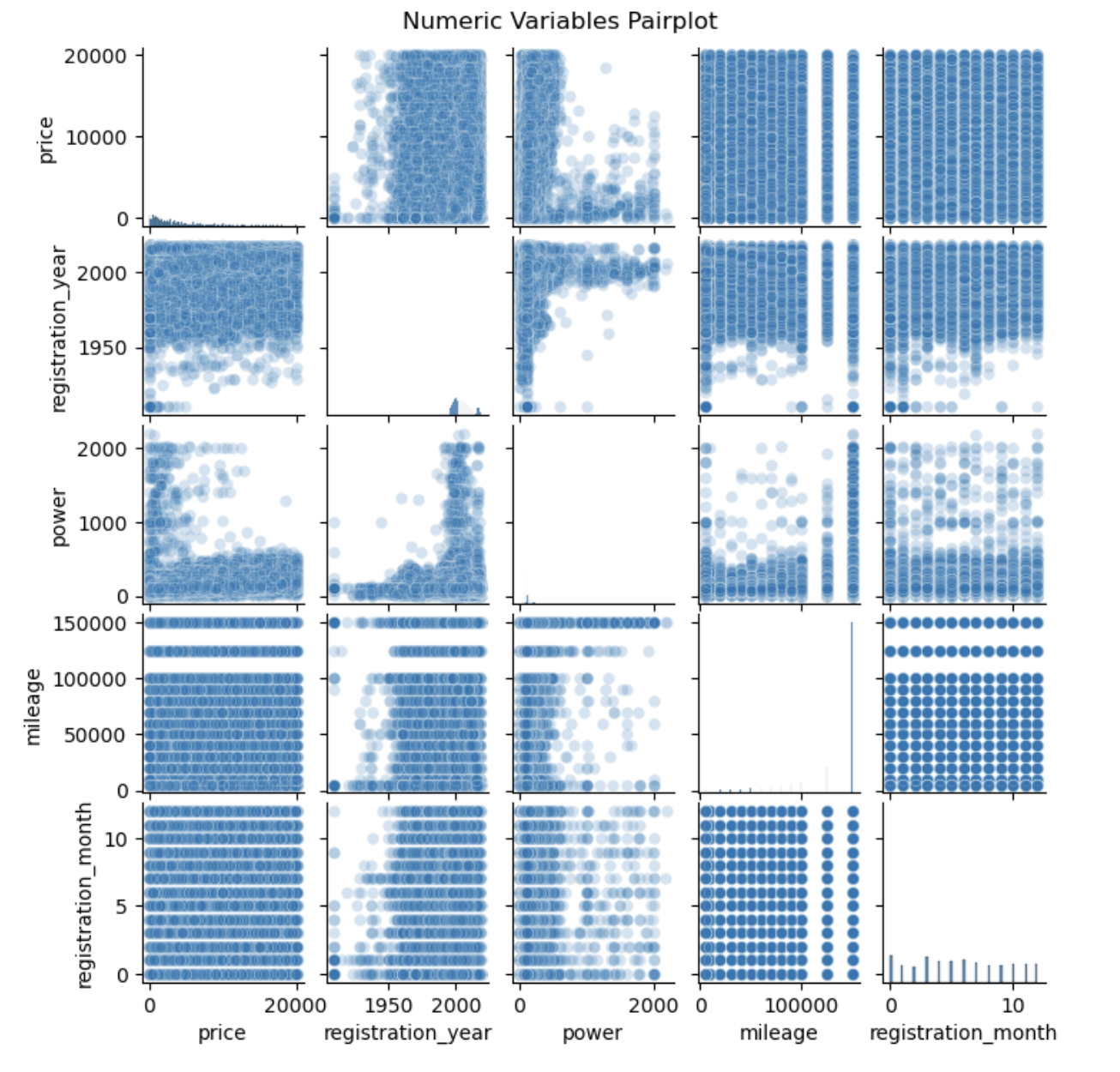
There are no clear associations between the dependent variable price and registriation_year, power, mileage, or registration_month. There is also a possible violation of linearity between price and power.
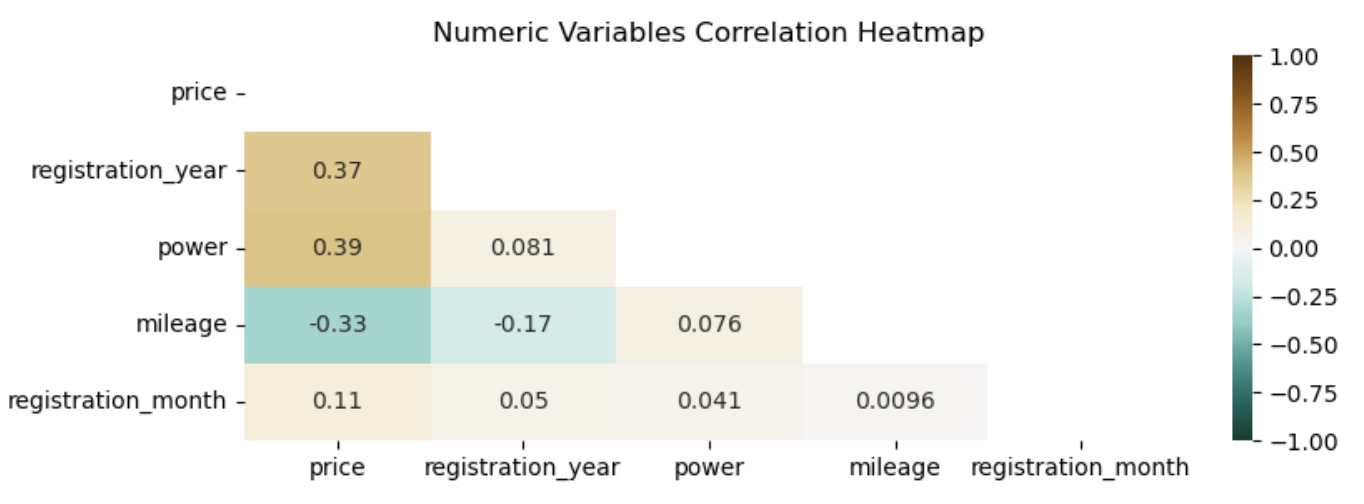
Price has a moderate, positive correlation with registration year (r = 0.37) and power (r = 0.40). Price has a moderate, negative correlation with mileage(r = -0.33). Price is only weakly related to registration month (r = 0.11). The features registration year, power, and mileage are very weakly correlated with each other. Multicollinearity is not an issue.
Train Results
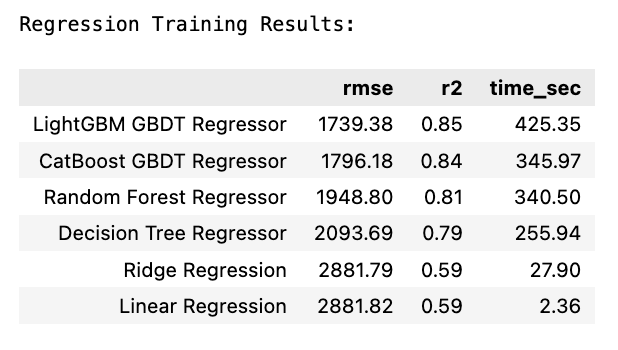
LightGBM achieved the lowest RMSE (RMSE = 1739.38) and highest R^2 value (R^2 = 0.85). LightGBM took the longest to tune, but this was due to the large number of hyperparameters entered into the grid. LightGBM was able to tune more hyperparameters options than Random Forest and CatBoost in a similar amount of time. Both standard and ridge regression had very quick computations, but they were over $1000 less accurate in their predictions than LightGBM GBDT. Considering both model score and time, LightGBM GBDT is the best model.
Test Results
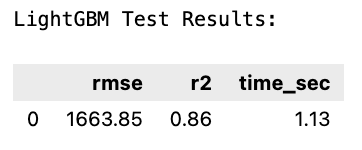
LightGBM GBDT achieved a lower RMSE and higher R^2 on the test set (RMSE = 1663.85, R^2 = 0.86). The model is likely not overfit. It was able to make predictions in less than one second.
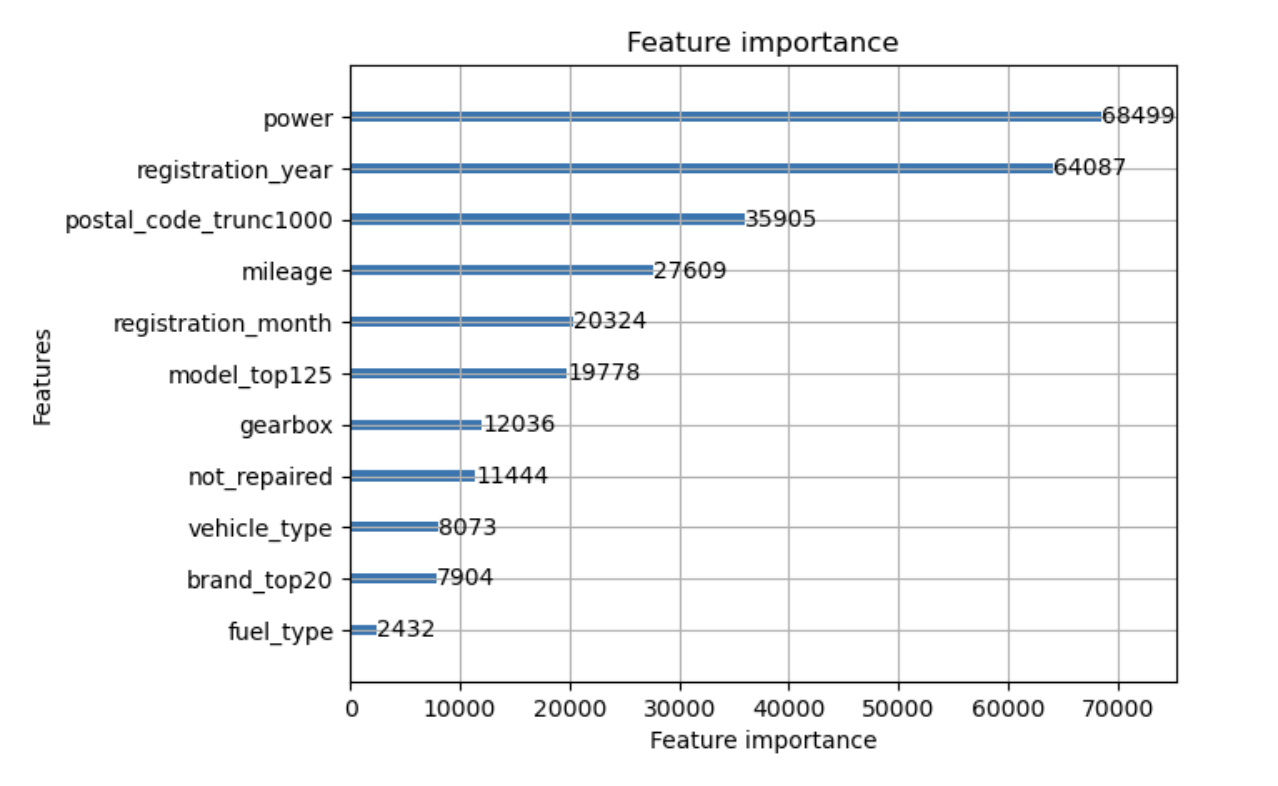
Power and registration_year are the most important features for predicting price. These are followed by postal code, mileage, registration month, and model type. The least important features are vehicle type, brand, and fuel type.
Conclusions and Business Application
Conclusions
LightGBM GBDT achieved the best model fit (RMSE test = 1663.83). Predictions from this model will offer customers the predicted value of their car within $1,663.83 on average. The most important features were predicting price were power, registration year, postal code, and mileage.
Business Application
Rusty Bargain will be able to implement this model in their app and be confident that customers will receive accurate predictions in about 1 second.
Future Research
With additional time, more hyperparameters and trees/iterations could be performed to improve model accuracy. Additionally, further data cleaning may improve the accuracy of the results.